 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective QA over Conflicting Multi-Source Personal Memory: A Diagnostic Testbed and Method Comparison
May 28, 2026Emerging personal AI agents are moving toward persistent, multi-source memory. This creates an evaluation problem: systems must decide how to use conflicting or incomplete evidence; they cannot just retrieve facts from one clean history. Existing benchmarks rarely show whether an error came from the evidence given to a method or from the method's conflict-resolution step. We study this as selective QA over conflicting multi-source personal memory: systems answer based on conflicting, sometimes incomplete sources, or abstain when evidence is insufficient. We develop a benchmark containing 18 question templates across 8 reasoning types, 480 personas, 4 random seeds, and 34,560 instances, with controlled source distortions and deterministic ground truth. We evaluate the performance of baselines without access to any source, access to a single source, structured fusion methods, and frontier LLMs. The best trained fusion resolver reaches 80.3% accuracy, while the strongest prompt-only LLM baseline reaches 70.0%. With abstention, the same resolver reaches 85.3% selective accuracy at 78.3% coverage and the best LLM reaches 71.0% selective accuracy at 95.4% coverage. Different models have different strengths across reasoning types. We release the data, code, cached model outputs, and data-generating process for reuse.
Prospect Theory in Physical Human-Robot Interaction: A Pilot Study of Probability Perception
Dec 09, 2025Understanding how humans respond to uncertainty is critical for designing safe and effective physical human-robot interaction (pHRI), as physically working with robots introduces multiple sources of uncertainty, including trust, comfort, and perceived safety. Conventional pHRI control frameworks typically build on optimal control theory, which assumes that human actions minimize a cost function; however, human behavior under uncertainty often departs from such optimal patterns. To address this gap, additional understanding of human behavior under uncertainty is needed. This pilot study implemented a physically coupled target-reaching task in which the robot delivered assistance or disturbances with systematically varied probabilities (10\% to 90\%). Analysis of participants' force inputs and decision-making strategies revealed two distinct behavioral clusters: a "trade-off" group that modulated their physical responses according to disturbance likelihood, and an "always-compensate" group characterized by strong risk aversion irrespective of probability. These findings provide empirical evidence that human decision-making in pHRI is highly individualized and that the perception of probability can differ to its true value. Accordingly, the study highlights the need for more interpretable behavioral models, such as cumulative prospect theory (CPT), to more accurately capture these behaviors and inform the design of future adaptive robot controllers.
D-LEAF: Localizing and Correcting Hallucinations in Multimodal LLMs via Layer-to-head Attention Diagnostics
Sep 09, 2025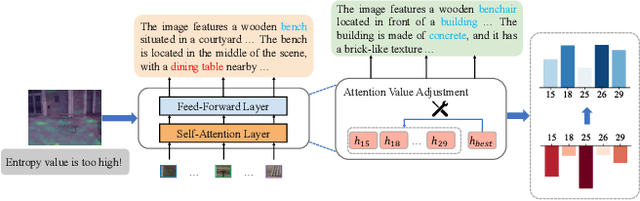

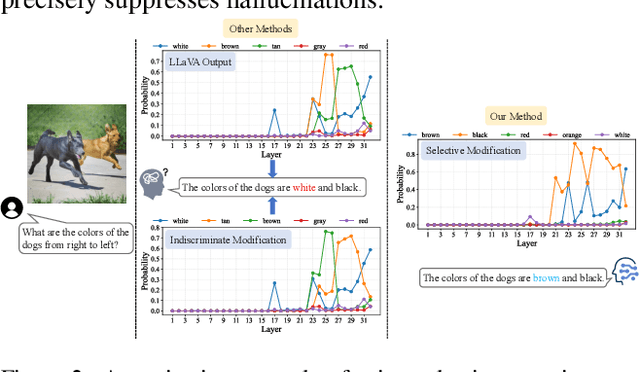
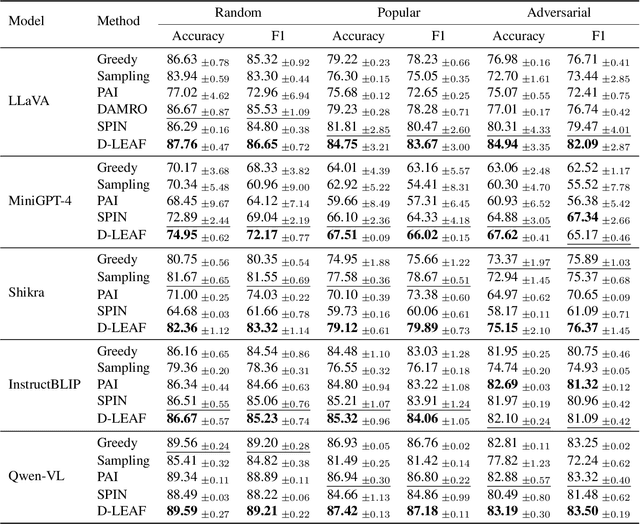
Multimodal Large Language Models (MLLMs) achieve strong performance on tasks like image captioning and visual question answering, but remain prone to hallucinations, where generated text conflicts with the visual input. Prior work links this partly to insufficient visual attention, but existing attention-based detectors and mitigation typically apply uniform adjustments across layers and heads, obscuring where errors originate. In this paper, we first show these methods fail to accurately localize problematic layers. Then, we introduce two diagnostics: Layer Image Attention Entropy (LIAE) which flags anomalous layers, and Image Attention Focus (IAF) which scores attention heads within those layers. Analysis shows that LIAE pinpoints faulty layers and IAF reliably ranks heads that warrant correction. Guided by these signals, we propose Dynamic Layer-wise Entropy and Attention Fusion (D-LEAF), a task-agnostic, attention-guided method that dynamically localizes and corrects errors during inference with negligible overhead. Results show our D-LEAF delivers a 53% relative improvement on standard captioning benchmarks, and on VQA both accuracy and F1-score improve by approximately 4%, substantially suppressing hallucinations while preserving efficiency.